Incident report for November 18, 2025
Detailed postmortem of the outage on November 18, 2025.
At Resend, we're accountable for delivering a reliable and resilient service, regardless of where an incident occurs.
On November 18, our customers experienced a service outage impacting their sending from 11:30 UTC to 14:31 UTC due to a wider Cloudflare outage.
All API traffic to Resend is proxied through Cloudflare. Requests enter Cloudflare's network and are then forwarded to our origin infrastructure in AWS. During this incident, this routing path failed, preventing requests from reaching our infrastructure.
We take full accountability for ensuring our services remain available and are resilient to failures, and this incident did not meet that expectation.
Incident overview
The Cloudflare outage directly affected Resend's API, Email API, SMTP and Dashboard. Because Cloudflare is the entry point for all traffic to api.resend.com, the incident prevented requests from reaching our infrastructure.
Cloudflare returned HTTP 500 errors at the edge before traffic could be routed to our AWS origins. As a result, no requests reached our backend services and all API calls failed. Our SMTP service was also impacted due to its dependency on api.resend.com.
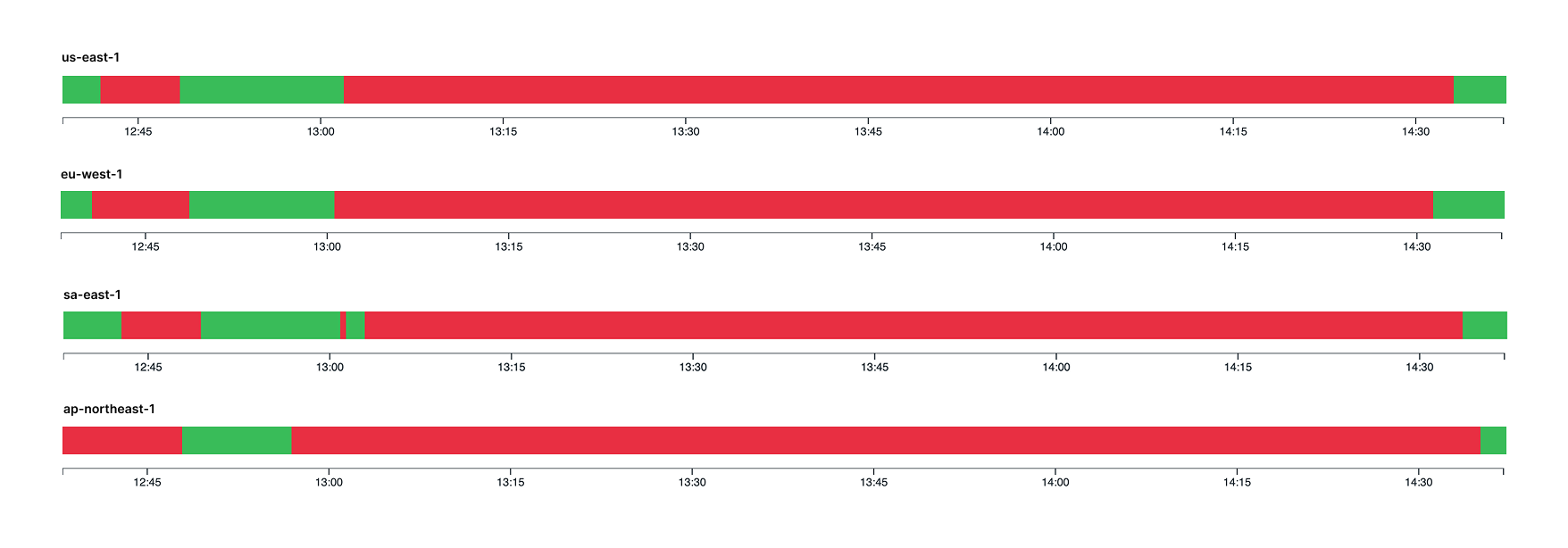
Our team was first alerted at 11:31 UTC for intermittent requests failing with a 500 response error, originating from Tokyo (ap-northeast-1) region. At first while monitoring and investigating the issue, we noticed monitors for other regions (us-east-1, sa-east-1 and eu-west-1) started to trigger intermittently with the same behavior. At 12:14 UTC, we started working on a workaround to bypass Cloudflare in an attempt to mitigate the incident and restore services.
Timeline (UTC)
- 11:30 — Automated tests detected the first intermittent failures on our API endpoints
- 11:48 — Cloudflare published a status update confirming an incident on their platform
- 11:53 — We observed problems in the Dashboard
- 11:56 — The issue was confirmed and our team began initial checks
- 11:56 — API calls to
api.resend.comstarted returningInternal Server Errorresponses - 11:59 — We confirmed that the outage was active across multiple regions and impacting multiple services
- 12:08 — Public incident created indicating an issue impacting all services
- 12:09 — Work began on a backup path using CloudFront to restore traffic if needed
- 13:15 — We began testing the CloudFront path and validating critical endpoints
- 14:31 — CloudFront backup stack deployed and ready for the DNS failover
- 14:31 — Monitoring showed that traffic was recovering as the upstream Cloudflare issue was remediated
The ALB traffic shows that Cloudflare connectivity was intermittent at first, but then failed for 1.5 hours.
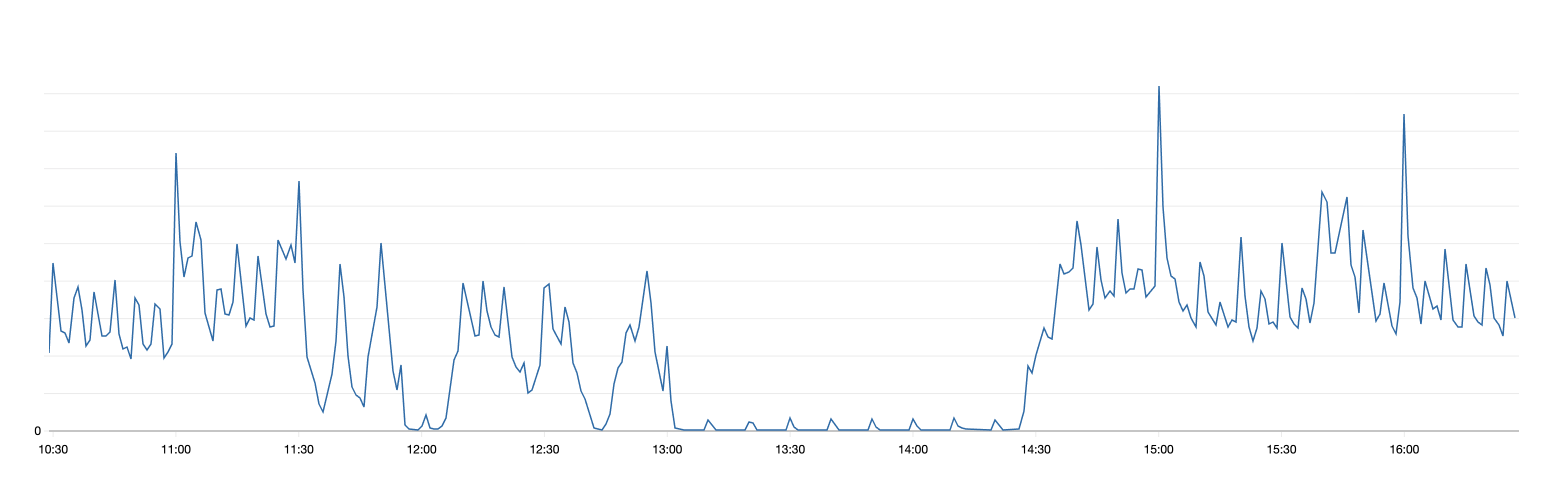
Datadog monitors for our APIs also showed a similar pattern.
Background
When a request is made, it reaches Cloudflare, is processed at the edge and then routed using Cloudflare Load Balancing, which forwards the traffic to the appropriate origin based on HTTP method and path. These endpoints are AWS Application Load Balancers (ALB) routing traffic to APIs hosted on ECS.
The traffic is split over two internal APIs known as:
- Email API: Handles the
/emailsroutes. - Resend API: Handles all the other API routes.
Cloudflare Load Balancing is used to send all POST /emails requests to the Email API and the rest to the Resend API.
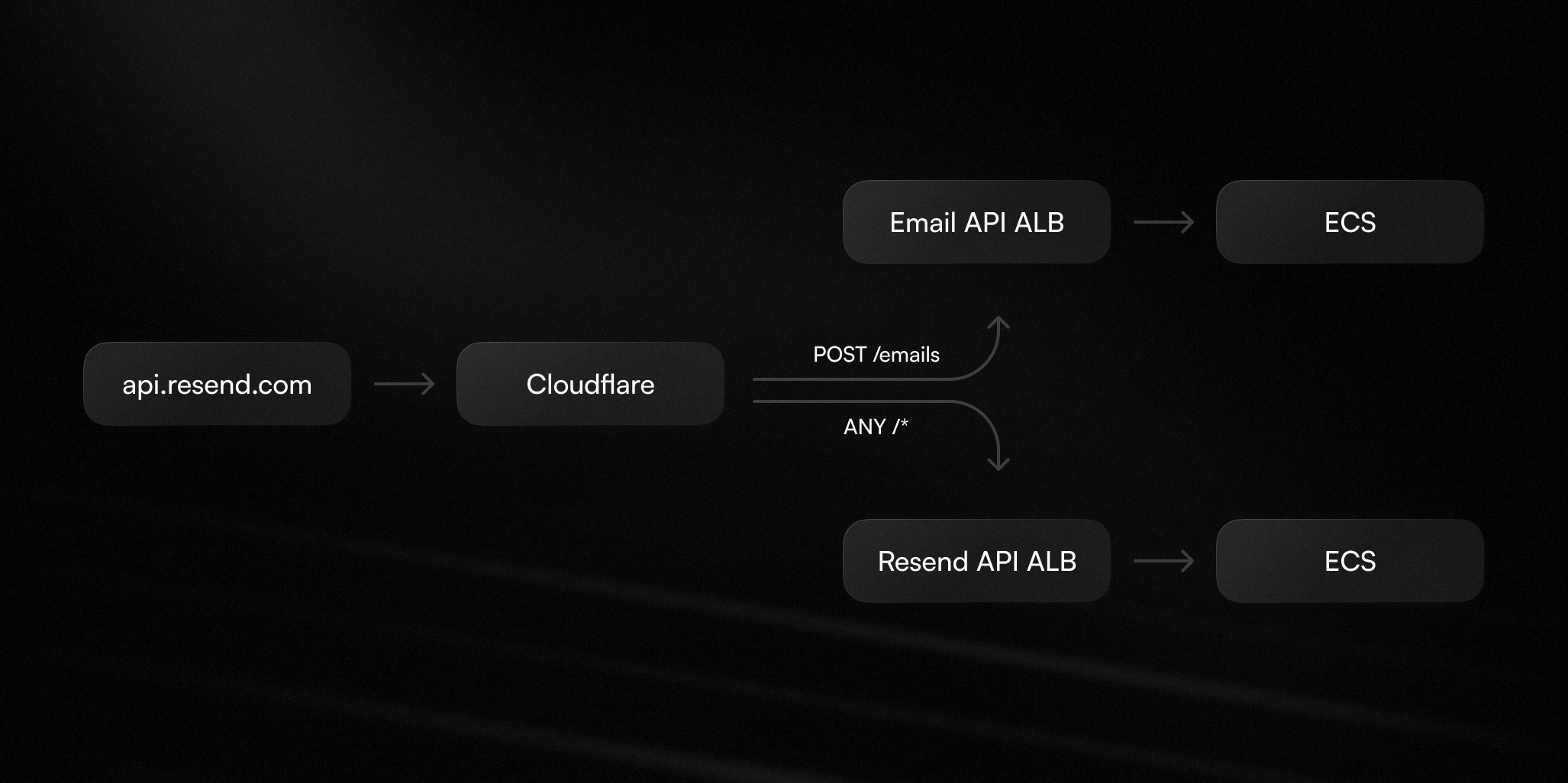
This load-balancing requirement made changing the entry point of our APIs more difficult than a single DNS entry to a different provider.
How we responded
After identifying that it was an issue with Cloudflare, we assessed all the services impacted, created a public status page and started working towards a resolution.
We determined that we need to work on a fix for our API entry points into Cloudflare and restore the critical email sending path first. We chose to move the API load balancing that was happening on Cloudflare to AWS CloudFront, since we already had the architecture and knowledge required to do so.
We took longer than we probably could have to deploy and test the solution. Various small issues delayed the fix, like figuring out CloudFront Function dynamic forwarding to AWS ALBs and header whitelisting. Once it was validated that it could work in the development environment, the IaC was reviewed and deployed into production.
We began testing and validated critical endpoints. Once we validated the few key endpoints, it was noted that traffic started to return to normal. We decided not to make the switch to reduce the unknown variables at play.
The CloudFront solution was not deployed, but the runbook was created. If the incident were to recur, we could switch to the fallback within 60 seconds. We continued to monitor and then closed the status page.
Moving forward
To prevent an outage like this from happening again, we're making long term improvements to our infrastructure.
Building resilience against vendor outages
We're making changes so that provider outages don't translate into Resend outages.
- Prepare a fallback entry point path to all our API traffic to quickly failover and re-route traffic in seconds to minimize downtime
- Ensure the critical email sending path remains available during third-party outages
Strengthening our incident response
We identified gaps in alerting and escalation that slowed our response.
- Fixed the misconfiguration that caused alerts to auto-resolve before escalating
- Adding new monitoring that can distinguish between issues inside Resend and issues at an external provider
- Creating war rooms earlier for critical incidents that affect multiple services
- Regular architecture reviews focused to reinforce the reliability in the critical paths
Hundreds of thousands of developers trust the email infrastructure every day. We see this kind of outage as unacceptable and apologize for the impact it has had on our users. Thank you for your trust and for your patience.